Introduction to Text to Speech (TTS)
What is text to speech? Text to speech (TTS) is a transformative technology that converts written text into spoken words using computer algorithms. By employing speech synthesis, TTS enables computers and apps to "read aloud" digital content. In 2025, TTS is deeply integrated into daily tech experiences, from accessibility tools to smart assistants, revolutionizing how users interact with information. This article will break down how text to speech works, its technology stack, and why it is essential for developers and end-users alike.
How Text to Speech Works
The Speech Synthesis Process
At the heart of text to speech lies speech synthesis, a multi-stage process that transforms raw text into natural-sounding speech. Here’s a high-level overview:
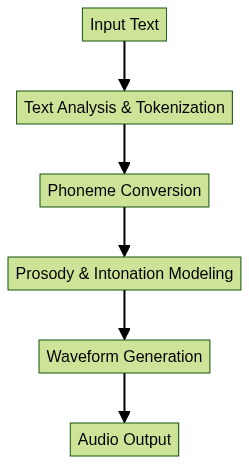
- Text Analysis & Tokenization: The system processes the input text, handling punctuation, abbreviations, and context.
- Phoneme Conversion: Words are broken into phonemes—the smallest units of sound.
- Prosody & Intonation Modeling: Rhythm, stress, and intonation are added for naturalness.
- Waveform Generation: The final audio signal is generated, often using neural networks.
Role of Artificial Intelligence and Machine Learning
Modern TTS systems leverage AI and machine learning for highly realistic voice synthesis. Deep learning models, such as Tacotron or WaveNet, analyze massive speech datasets to learn nuances in pronunciation and prosody. Developers looking to add interactive voice features can explore platforms like
Voice SDK
, which offer robust APIs for integrating real-time audio capabilities into applications.Here’s a basic example of using a TTS API in Python (Google Cloud TTS):
1import os
2from google.cloud import texttospeech
3
4client = texttospeech.TextToSpeechClient()
5
6synthesis_input = texttospeech.SynthesisInput(text="What is text to speech?")
7voice = texttospeech.VoiceSelectionParams(
8 language_code="en-US",
9 ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
10)
11audio_config = texttospeech.AudioConfig(
12 audio_encoding=texttospeech.AudioEncoding.MP3
13)
14
15response = client.synthesize_speech(
16 input=synthesis_input,
17 voice=voice,
18 audio_config=audio_config
19)
20
21with open("output.mp3", "wb") as out:
22 out.write(response.audio_content)
23Types of Text to Speech Tools
Built-in TTS Features in Operating Systems
Major OS platforms, like Windows, macOS, and Linux distributions, include native text to speech engines. These are easily accessible through system settings or accessibility options. Advantages include system-wide integration and offline support. However, customization and voice quality can be limited.
Web-based and App-based TTS Solutions
SaaS applications and mobile apps (such as NaturalReader or Speech Central) provide cloud-based TTS with advanced features like multi-language support, high-quality neural voices, and real-time streaming. For developers interested in adding interactive audio to their apps, a
Live Streaming API SDK
can be a valuable tool for building scalable, real-time voice and video experiences. Pros: always updated, scalable, and feature-rich. Cons: dependency on internet connectivity and potential data privacy risks.Chrome Extensions and Browser Tools
Browser-based TTS tools, like Read Aloud or Speechify extensions, offer in-browser text reading and integration with web content. They are easy to install and use but may lack deep customization and sometimes have limited language support.
Key Applications and Use Cases of Text to Speech
Accessibility for People with Disabilities
TTS is a cornerstone of digital accessibility. It enables users with visual impairments, dyslexia, or learning difficulties to access digital and online content independently. For those seeking to integrate calling features for accessibility, a
phone call api
can help build voice-enabled communication tools.Virtual Assistants and Smart Devices
Smart assistants like Google Assistant, Alexa, and Siri utilize TTS to deliver answers, notifications, and read messages. The technology also powers voice feedback in IoT devices. Developers building communication apps may also benefit from a
Video Calling API
to enable seamless audio and video interactions alongside TTS.Content Consumption and Productivity
Text to speech helps users consume articles, emails, and ebooks hands-free. Features like text highlighting and OCR (Optical Character Recognition) allow TTS to read scanned documents and PDFs. If you want to
embed video calling sdk
alongside TTS features, prebuilt solutions can accelerate your development process.Gaming and Streaming
Streamers use TTS for chat interactions and donation alerts. Here’s an example setup for Streamlabs/OBS with a browser source:
- Add a new "Browser Source" in OBS.
- Paste the URL of your TTS widget (from Streamlabs or similar).
- Configure voice, volume, and message settings in the Streamlabs dashboard.
- Test the setup by sending a message or donation.
This enables audience messages to be read aloud during live streams, improving interactivity. For advanced audio experiences in live audio rooms, developers can utilize a
Voice SDK
to create engaging, interactive environments for their audience.Benefits of Using Text to Speech
Improving Accessibility
TTS empowers users with disabilities by bridging content gaps, ensuring compliance with accessibility standards such as WCAG 2.1.
Enhancing Comprehension and Focus
By hearing text read aloud, users can better retain information and maintain focus—especially useful in education and training contexts. Integrating a
Voice SDK
can further enhance learning platforms by adding real-time voice discussions and collaborative features.Multitasking and Convenience
TTS allows users to listen to documents, emails, or articles while on the move, increasing productivity and convenience. For developers working in Python, leveraging a
python video and audio calling sdk
can help add both TTS and real-time communication features to their applications.Technical Overview: How to Implement Text to Speech
Using APIs
Developers can quickly add TTS using APIs from providers like Google Cloud, Microsoft Azure, or AWS Polly. Here’s a simple example using Google Cloud TTS API:
1import os
2from google.cloud import texttospeech
3
4client = texttospeech.TextToSpeechClient()
5
6input_text = texttospeech.SynthesisInput(text="Text-to-speech implementation demo.")
7voice = texttospeech.VoiceSelectionParams(
8 language_code="en-US",
9 ssml_gender=texttospeech.SsmlVoiceGender.FEMALE
10)
11audio_config = texttospeech.AudioConfig(
12 audio_encoding=texttospeech.AudioEncoding.MP3
13)
14
15response = client.synthesize_speech(
16 input=input_text,
17 voice=voice,
18 audio_config=audio_config
19)
20
21with open("tts_demo.mp3", "wb") as out:
22 out.write(response.audio_content)
23Integration into Websites and Apps
TTS functionality can be integrated at various levels. Here’s a workflow diagram illustrating a typical web app integration:

For those building interactive voice features, a
Voice SDK
can streamline the process of adding live audio rooms or group calls to your web or mobile apps.Open Source and Commercial Options
Open source TTS frameworks like Mozilla TTS or eSpeak allow for self-hosted, customizable solutions. Commercial APIs offer premium voice quality, language support, and advanced features, but may incur costs and have usage restrictions.
Common Issues and Troubleshooting in Text to Speech
- Voice Quality and Naturalness: Synthetic voices may sound robotic if not using state-of-the-art neural models.
- Language and Accent Support: Not all TTS engines support every language or dialect.
- Handling Complex Text and OCR: Abbreviations, technical jargon, and scanned documents require preprocessing and OCR for accurate pronunciation.
Text to Speech vs. Voice Response Systems
While TTS focuses on converting text to spoken output, Voice Response Systems (VRS) are interactive platforms that process voice input and respond, often combining Automatic Speech Recognition (ASR) with TTS. TTS is a component, but VRS covers broader dialog management and user input handling.
The Future of Text to Speech Technology
By 2025, TTS is advancing with AI-driven voice cloning, emotional modeling, and real-time translation. Applications are broadening—from accessibility to gaming, robotics, and multilingual communications—making TTS a vital part of the modern digital landscape. Developers can
Try it for free
to explore the latest TTS and voice integration tools.Conclusion
Understanding what is text to speech is essential for leveraging its full potential in accessibility, productivity, and emerging AI-powered applications in 2025.
FAQ